Stores Raw Data In A Relational Database
Breaking News Today
Mar 28, 2025 · 6 min read
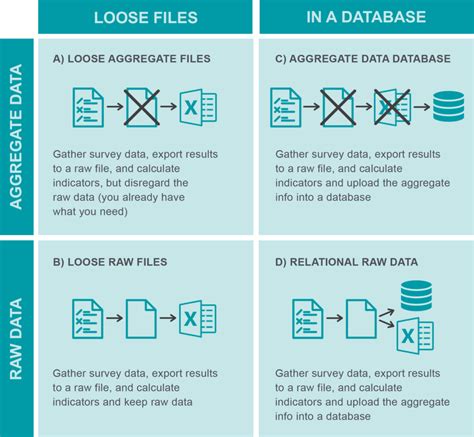
Table of Contents
Storing Raw Data in a Relational Database: A Comprehensive Guide
Storing raw data effectively is crucial for any organization seeking to leverage the power of data analytics and business intelligence. While various data storage solutions exist, relational databases remain a popular and robust choice, particularly for structured data. This comprehensive guide delves into the intricacies of storing raw data in a relational database, covering best practices, potential challenges, and strategies for optimization.
Why Choose a Relational Database for Raw Data?
Relational databases, often referred to as RDBMS (Relational Database Management Systems), such as MySQL, PostgreSQL, Oracle, and SQL Server, offer several advantages for raw data storage:
1. Data Integrity and Consistency:
- ACID Properties: RDBMS adhere to ACID properties (Atomicity, Consistency, Isolation, Durability), ensuring data transactions are reliable and maintain data integrity even during failures or concurrent access. This is critical for preserving the accuracy of your raw data.
- Constraints and Validation: You can implement constraints like data types, primary keys, foreign keys, and check constraints to enforce data validation rules. This prevents the entry of inconsistent or invalid data, ensuring data quality from the outset.
- Data Normalization: Techniques like database normalization help organize data efficiently, reducing redundancy and improving data consistency.
2. Structured Query Language (SQL):
- Powerful Querying: SQL provides a powerful and standardized language for querying, manipulating, and managing data within the database. This allows for complex data analysis and retrieval with ease.
- Data Manipulation: SQL simplifies tasks like data insertion, updating, deletion, and aggregation. These capabilities are essential for data processing and transformation pipelines.
- Data Reporting: SQL facilitates the creation of reports and dashboards directly from the raw data, providing valuable insights.
3. Scalability and Performance:
- Scalability Options: Modern RDBMS offer various scalability options, including horizontal scaling (adding more servers) and vertical scaling (increasing server resources). This ensures the database can handle growing data volumes and user traffic.
- Indexing and Optimization: Indexes and query optimization techniques significantly enhance database performance, enabling faster data retrieval and improved application responsiveness.
- Transaction Management: Efficient transaction management minimizes conflicts and maximizes concurrency, further boosting performance.
4. Security and Access Control:
- User Roles and Permissions: RDBMS provide robust mechanisms for managing user access and permissions, ensuring only authorized personnel can access and modify sensitive raw data.
- Data Encryption: Data encryption features help protect data from unauthorized access and breaches.
- Auditing: Many RDBMS offer auditing capabilities, allowing you to track data changes and identify potential security issues.
Designing Your Relational Database for Raw Data:
Effective storage of raw data in a relational database requires careful planning and design. Here are some key considerations:
1. Data Modeling:
- Identify Entities and Attributes: Begin by identifying the key entities (e.g., customers, products, transactions) and their associated attributes (e.g., customer ID, name, address, product ID, price, transaction date).
- Establish Relationships: Define the relationships between different entities (e.g., one-to-one, one-to-many, many-to-many). This dictates how tables are linked and data is organized.
- Choose Data Types: Carefully select appropriate data types for each attribute (e.g., INT, VARCHAR, DATE, FLOAT) to ensure data integrity and efficiency.
2. Table Design:
- Normalization: Apply normalization principles to minimize data redundancy and improve data consistency. Aim for at least third normal form (3NF) for most applications.
- Primary and Foreign Keys: Define primary keys to uniquely identify each record within a table and foreign keys to establish relationships between tables.
- Indexing: Strategically create indexes on frequently queried columns to speed up data retrieval.
3. Data Cleaning and Transformation:
- Data Validation: Implement data validation rules to ensure data quality before it enters the database. This prevents errors and inconsistencies.
- Data Transformation: Transform data into a consistent format before loading it into the database. This might involve data type conversions, data cleaning, and data standardization.
- Error Handling: Implement robust error handling mechanisms to manage and log errors during data loading and processing.
Handling Different Data Types in a Relational Database:
Relational databases can handle various data types, but certain strategies are beneficial for optimal storage and querying:
1. Structured Data:
- Tables and Columns: Structured data fits naturally into the tabular format of relational databases. Each data point is neatly organized into rows and columns.
- Data Integrity Constraints: Use constraints to maintain data integrity and consistency.
- SQL Queries: Leverage SQL for efficient querying and analysis.
2. Semi-structured Data (e.g., JSON, XML):
- JSON/XML Columns: Store semi-structured data as text within dedicated columns. Specialized functions or external tools might be needed for parsing and querying this data.
- NoSQL Alternatives: For large volumes of semi-structured data, consider a NoSQL database alongside your relational database.
- Data Transformation: Pre-process semi-structured data to extract relevant information before loading it into relational tables.
3. Unstructured Data (e.g., text, images, audio):
- External Storage: Store unstructured data in external storage systems (e.g., cloud storage, file systems) and store only metadata (e.g., file path, file size) in the relational database.
- Limited Relational Use: Relational databases are not ideal for storing large volumes of unstructured data. Focus on managing metadata within the RDBMS.
Best Practices for Storing Raw Data:
- Data Governance: Establish clear data governance policies to ensure data quality, consistency, and security.
- Version Control: Implement a system for tracking changes to the raw data and allowing for rollbacks if necessary.
- Data Backup and Recovery: Regularly back up your database to protect against data loss. Implement a robust recovery plan.
- Monitoring and Performance Tuning: Monitor database performance and identify bottlenecks. Tune the database to optimize performance.
- Security Audits: Regularly conduct security audits to identify and address potential vulnerabilities.
Challenges and Considerations:
- Data Volume: Storing and managing large volumes of raw data can present performance and scalability challenges.
- Data Velocity: High-velocity data streams might require specialized techniques for data ingestion and processing.
- Data Variety: Handling diverse data types can require complex data modeling and processing techniques.
- Data Veracity: Ensuring data quality and accuracy is crucial for reliable analysis.
- Cost: The cost of storing and managing large datasets in a relational database can be significant.
Choosing the Right Relational Database:
The choice of relational database depends on various factors, including:
- Data Volume and Velocity: Select a database that can handle the expected data volume and velocity.
- Scalability Requirements: Choose a database that can scale horizontally or vertically as needed.
- Features and Functionality: Consider the database's features and functionality, such as built-in security, replication, and high availability.
- Cost: Compare the costs of different databases, including licensing fees, maintenance, and infrastructure costs.
- Community Support: Choose a database with a strong community and ample online resources.
Conclusion:
Storing raw data in a relational database offers significant advantages in terms of data integrity, consistency, querying capabilities, and security. However, careful planning, design, and ongoing management are essential for success. By understanding the best practices, potential challenges, and available technologies, organizations can effectively leverage relational databases to harness the power of their raw data for insightful analysis and strategic decision-making. Remember to always prioritize data governance, security, and scalability to ensure long-term success in your data management strategy.
Latest Posts
Latest Posts
-
Which Of The Following Is An Example Of Operant Conditioning
Mar 31, 2025
-
A Rapid Irregular Heartbeat Is A Symptom Of Quizlet
Mar 31, 2025
-
Amoeba Sisters Video Recap Mutations Updated Answer Key Quizlet
Mar 31, 2025
-
Describe The Symptoms And Treatment For Athletes Foot Quizlet
Mar 31, 2025
-
End Of Life Palliative Care And Hospice Care Quizlet
Mar 31, 2025
Related Post
Thank you for visiting our website which covers about Stores Raw Data In A Relational Database . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
